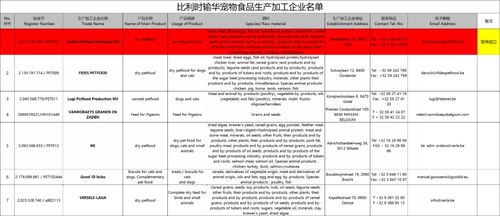
中國海關總署發布通知,宣布暫停批準進口比利時聯合公司(United Petfood Producers NV)生產的寵物食品。這一舉措在寵物食品行業中引起了廣泛關注,特別是考慮到該公司以其在中國市場獲批的寵物食品進口證數量之多而聞名。作為歐洲主要的寵物食品代工廠之一,比利時聯合公司的產品廣泛供應給多個國內外知名寵物食品品牌,并通過線上線下渠道在中國市場銷售。
此次暫停進口的決定主要基于海關在近期對進口寵物食品進行的質量安全風險評估和監測中發現的問題。雖然具體細節尚未公開,但通常此類措施與產品安全性、標簽合規性或檢疫標準相關。中國海關近年來持續加強對進口寵物食品的監管,確保其符合國家食品安全標準,以保護國內消費者和寵物的健康。
這一事件對寵物食品市場產生了直接沖擊。依賴比利時聯合公司作為代工廠的品牌可能面臨供應鏈中斷的風險,導致產品短缺和價格上漲。消費者在線上平臺購買寵物食品時,需更加謹慎,留意產品來源和進口資質,以避免購買到可能受影響的產品。網絡銷售渠道作為寵物食品的重要分銷途徑,預計將受到嚴格審查,平臺方可能加強賣家資質審核和產品信息公示。
從行業角度來看,這次暫停進口事件凸顯了中國監管機構對寵物食品質量安全的高度重視。隨著養寵人群的擴大和消費升級,寵物食品市場快速增長,但同時也暴露出一系列問題,如虛假宣傳、添加劑超標等。此次行動可能是一個信號,預示著未來進口寵物食品將面臨更嚴格的準入標準和常態化的監督檢查。企業需加強合規管理,確保從原料采購到生產出口的全鏈條符合中國法規。
對于消費者而言,建議在購買進口寵物食品時,優先選擇有明確海關進口記錄和正規渠道的產品,并關注官方發布的食品安全信息。這也為國內寵物食品品牌提供了機遇,通過提升產品質量和安全性,增強市場競爭力。
比利時聯合公司進口資格的暫停,不僅是一次具體的監管行動,更是寵物食品行業整體規范化發展的縮影。在保障寵物健康與食品安全的大背景下,企業、平臺和消費者都需共同努力,推動市場向更透明、更可靠的方向邁進。隨著監管措施的持續完善,中國寵物食品市場有望實現更高質量的增長。